What is the systematic approach to processing and analyzing large-scale data? A robust, efficient data processing framework is essential for extracting value from vast datasets.
This framework, often implemented as a series of interconnected stages, handles various tasks, such as data ingestion, transformation, validation, and output. Each stage is designed to prepare the data for subsequent analyses, ensuring accurate and reliable results. A well-defined pipeline can dramatically improve the efficiency of data management and analysis projects, accommodating intricate processes within a structured environment. This streamlined workflow enables organizations to tackle substantial datasets with greater speed and accuracy.
Such a pipeline is crucial for modern data-driven decision-making. By automating processes and standardizing workflows, it allows organizations to gain insights faster. The reliability and consistency provided by a robust pipeline contribute significantly to the quality of data-derived conclusions. Historical context highlights the increasing importance of efficient data handling, as data volumes have exploded in recent years. The need for robust data processing solutions is undeniable, enabling data-driven strategies and actionable insights.
Moving forward, let's delve into the specifics of designing and implementing such a data processing system. Different types of data will demand specialized pipelines, and a clear understanding of these needs is paramount. Crucially, scalability and adaptability will be discussed.
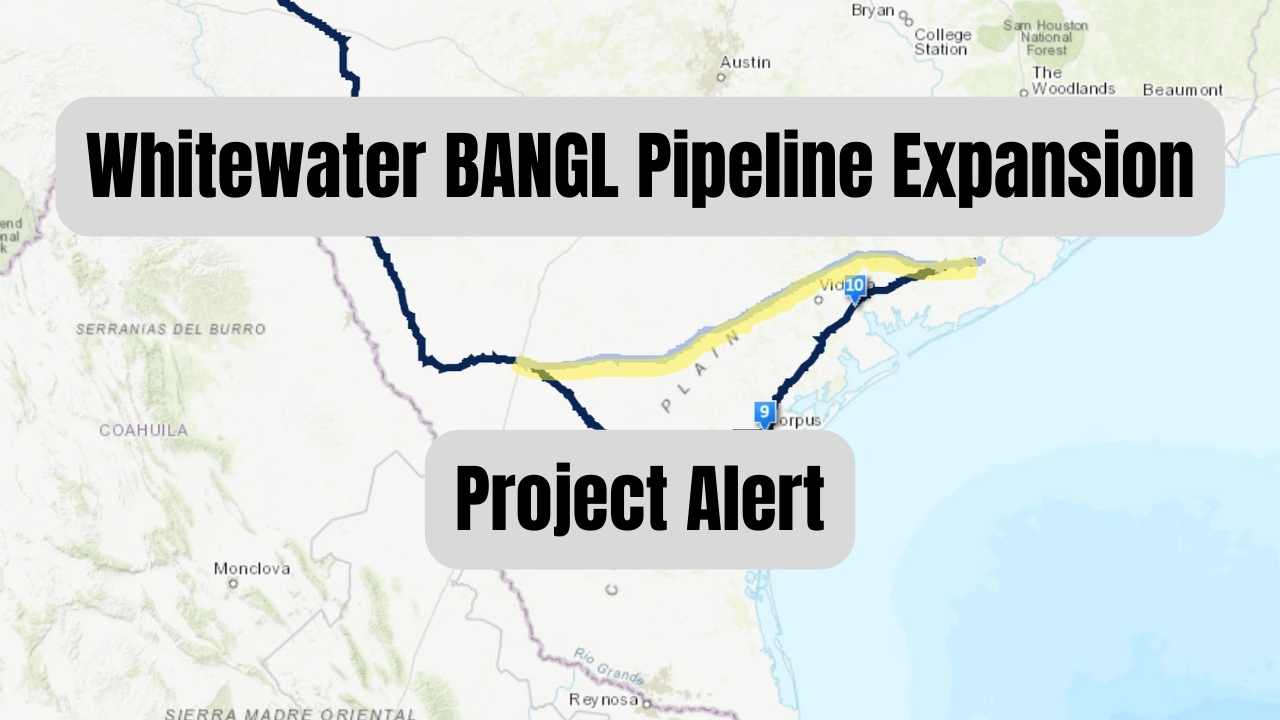
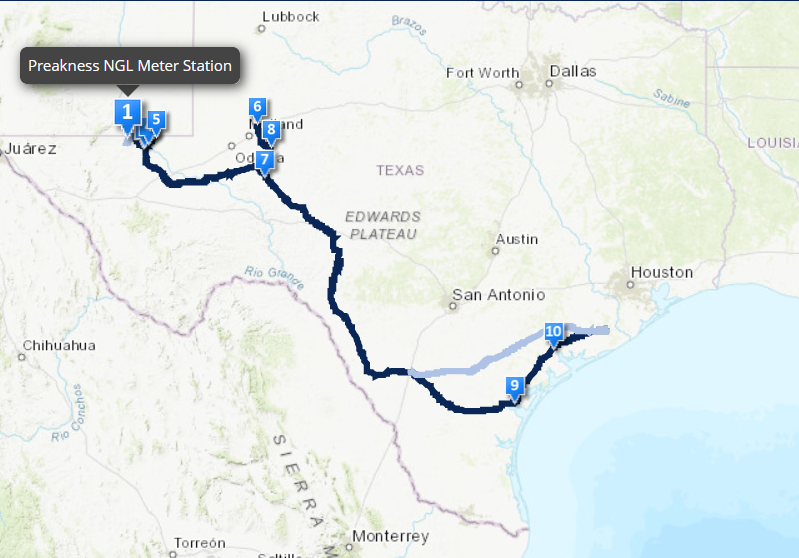
Bangl Pipeline
A robust "bangl pipeline" is vital for efficient data processing, encompassing various stages from input to output. Its effectiveness hinges on carefully considered aspects.
- Data Ingestion
- Transformation
- Validation
- Output Delivery
- Scalability
- Automation
- Security
- Monitoring
These aspects function interdependently. Data ingestion involves capturing raw data from various sources. Transformation ensures the data is in a usable format. Validation checks data quality and accuracy. Output delivery determines where processed data is sent. Scalability accommodates growing data volumes. Automation streamlines processes. Security protects sensitive data throughout the pipeline. Monitoring allows for real-time process evaluation and adjustments. For example, a robust financial transaction processing system necessitates rigorous security measures at each stage, while a social media analysis pipeline might emphasize scalability and speed of data delivery. Understanding the interplay and importance of these components ensures a comprehensive and effective data processing framework.
1. Data Ingestion
Data ingestion, a critical initial stage within a data processing pipeline, defines how raw data enters the system. Its effectiveness profoundly influences subsequent analysis. The quality and efficiency of this stage directly impact the reliability and value of the overall output.
- Source Variety and Complexity
Data originates from diverse sources, including databases, APIs, files (structured and unstructured), and streaming feeds. The heterogeneity of these sources necessitates adaptable ingestion methods. Handling different data formats, speeds, and volumes requires careful design and implementation. For instance, ingesting data from a real-time sensor network demands a different approach than ingesting data from a batch file upload.
- Data Validation and Cleansing at Ingestion
Early identification of issues in incoming data is crucial. Invalid or incomplete data can lead to downstream errors. Robust ingestion systems often incorporate validation routines to filter unwanted data, handle missing values, and detect anomalies. This prevents the propagation of errors through the pipeline, ensuring quality data is used for subsequent analysis.
- Data Transformation Before Processing
Raw data frequently requires transformation to align with the downstream processing needs. This could involve reformatting, data type conversions, or feature engineering. Such transformations often occur within the ingestion stage or immediately thereafter, to conform data to a consistent, usable format. Data cleaning and transformation are vital for the integrity of subsequent analyses within the pipeline.
- Scalability and Performance Requirements
Effective data ingestion must handle increasing data volumes and velocities. Scalable solutions are necessary to accommodate fluctuating data flows. High-throughput ingestion and efficient data storage are vital to maintain the responsiveness of the pipeline. Real-time applications demand specific ingestion strategies with high throughput and low latency to meet performance requirements.
In summary, the effectiveness of a data processing pipeline is significantly determined by the design and execution of the ingestion stage. A well-structured ingestion process ensures high-quality data input, crucial for the reliability and value of the subsequent stages. The diverse nature of data sources, stringent validation, necessary transformations, and efficient handling of increasing volumes contribute to the integrity and scalability of the overall pipeline.
2. Transformation
Transformation within a data processing pipeline is a critical intermediary stage. It modifies raw data into a usable format suitable for subsequent analysis. This stage ensures data consistency and accuracy, enabling effective downstream processes. Its role is multifaceted and essential for the overall pipeline's functionality and effectiveness.
- Data Cleansing and Preparation
This involves identifying and correcting errors, handling missing values, and normalizing data formats. Data cleaning is crucial for preventing downstream errors and inaccuracies. For instance, removing duplicates, standardizing dates, and converting inconsistent formats into a common structure are examples of this activity. Errors in this step can cascade through the pipeline and lead to flawed results, hence the rigor demanded.
- Feature Engineering and Selection
This process focuses on creating new, meaningful features from existing data. New features can be derived from combinations of existing attributes, derived metrics, or engineered features based on domain knowledge. For example, from raw transaction data, new features like "average purchase amount per customer" or "frequency of purchases" can be derived. Appropriate selection and engineering can substantially enhance the predictive power of subsequent analyses.
- Data Aggregation and Summarization
This involves consolidating data from multiple sources or granular levels into higher-level summaries and aggregates. Grouping data by certain attributes, calculating aggregate measures like sums, averages, or counts, and creating summary statistics are core components. For example, aggregating sales data by region, product type, or time period facilitates comprehensive analysis and reporting.
- Data Transformation for Different Applications
Different applications require different data formats. Transformation ensures the data aligns with the specific needs of downstream systems or models. This could involve converting data types, rearranging columns, or mapping values. An example might be converting raw sensor data into a standardized format usable by a machine learning model.
Effective transformation significantly impacts the quality and usability of data for downstream tasks in a "bangl pipeline." Without appropriate preparation, data quality issues can severely affect results. Careful consideration of cleansing, feature engineering, aggregation, and application-specific adjustments is paramount for an effective pipeline, maximizing the insights extracted and ensuring accuracy and reliability in the analyses.
3. Validation
Validation within a data processing pipeline, often termed a "bangl pipeline," is a critical stage ensuring data integrity and reliability. Its function extends beyond mere verification; it's an active process of assessing data quality and accuracy. This stage directly impacts the subsequent stages' effectiveness and ultimately the trustworthiness of insights derived from the processed data. Failure to validate effectively can lead to flawed downstream analyses and erroneous conclusions, especially critical in fields like finance, healthcare, or scientific research. Examples range from identifying inconsistencies in financial transaction records to detecting inaccuracies in patient medical data.
A robust validation process involves multiple checks and balances, employing various techniques like data type verification, format consistency checks, range checks (ensuring values fall within expected bounds), and comparing data against external references. Crucially, validation must be integrated seamlessly into the pipeline, ideally at multiple points throughout. For instance, incoming data can be validated against predefined schemas, identifying and correcting discrepancies at the ingestion stage. Ongoing validation during transformation can detect anomalies or errors introduced through transformations, ensuring integrity throughout the process. Furthermore, validation should encompass checks for data completeness, identifying missing values or incomplete records. Consider the practical application: a validation step in a manufacturing pipeline could check that each component's specifications meet design standards. Failure to validate at each step introduces accumulated errors, making the entire "bangl pipeline" less dependable. A thorough validation strategy is vital to mitigate risks and enhance the value of the overall process.
In summary, validation in a data processing pipeline plays a pivotal role in maintaining data quality and reliability. Its integration at various stages, employing appropriate techniques and checks, ensures the accuracy and consistency of the processed data, ultimately leading to more reliable insights and actionable results. Omitting or inadequately performing this stage can have severe implications, particularly when dealing with high-stakes or consequential decisions. A comprehensive validation strategy is not simply a checklist but a proactive process that safeguards the integrity of the "bangl pipeline" and the value of the data it processes.
4. Output Delivery
Output delivery, a crucial concluding stage in a data processing pipeline ("bangl pipeline"), directly impacts how processed information is utilized and disseminated. Effective delivery mechanisms translate data analysis into actionable insights, fostering informed decisions and facilitating strategic initiatives within organizations. The approach to output delivery must align with the specific needs and goals of the recipient, ensuring data accessibility and facilitating its subsequent use.
- Data Destination and Format
A key aspect of output delivery is determining the intended destination of the processed data. This could range from databases for storage and retrieval to dashboards for real-time monitoring or specialized reports for specific stakeholders. The choice of destination directly influences the appropriate format for the output. For instance, data intended for a machine learning model might need a specific structured format, while data for a business presentation might benefit from a summarized, visually engaging layout. Mismatched formats can hinder downstream utilization.
- Accessibility and Security Measures
Data access must be carefully managed to prioritize security and confidentiality. Appropriate access controls and permissions should be implemented to restrict access based on user roles and responsibilities. This crucial step minimizes data breaches and unauthorized use. Specific delivery mechanisms, such as secure file transfer protocols or encrypted data streams, are often mandated. Consideration should be given to compliance with regulations and industry standards.
- Real-time vs. Batch Processing
The output delivery strategy must align with the nature of the data processing. Real-time data requires rapid delivery mechanisms to enable immediate updates and responsiveness. Batch processing, on the other hand, often involves scheduled delivery of processed data in bulk. The selected approach determines the specific tools and infrastructure needed for effective output delivery. A financial trading platform, for example, critically demands real-time delivery of market data, while a quarterly report requires batch processing.
- Feedback and Monitoring Mechanisms
Robust output delivery often incorporates mechanisms for feedback and monitoring. This allows for validation of the data's accuracy and completeness upon arrival. Tracking data delivery and reporting any issues or delays promptly support efficient troubleshooting. Error logging and alerts are vital for timely intervention. These elements not only enhance data reliability but also facilitate continuous pipeline improvement.
Effective output delivery is integral to the overall success of a data processing pipeline. It ensures processed data is accessible, secure, and appropriately formatted for its intended use. This critical step is crucial for deriving value from the data processed and enables informed decision-making. A well-designed output delivery system contributes significantly to the entire pipeline's efficiency and effectiveness, directly influencing the ultimate value realized by the organization.
5. Scalability
Scalability, in the context of a data processing pipeline (often referred to as a "bangl pipeline"), is paramount for long-term viability and effectiveness. A pipeline designed without consideration for future growth will likely become a bottleneck as data volumes and processing needs expand. Adaptability to increasing workloads and data streams is critical for maintaining operational efficiency and deriving maximum value from the processed data.
- Handling Growing Data Volumes
Data volumes are inherently dynamic and often increase exponentially. A scalable pipeline must accommodate this growth without degrading performance. This necessitates strategies like distributed processing, data partitioning, and utilizing cloud-based infrastructure. For example, a social media analytics pipeline must handle ever-expanding datasets of user interactions, posts, and comments. Inability to scale would lead to delays and a decline in the quality and timeliness of insights derived.
- Adaptability to Varying Processing Demands
Processing demands may fluctuate based on various factors such as seasonal trends, specific events, or changes in business priorities. A flexible pipeline must respond to these changes without disrupting existing functionalities. This might involve adapting resource allocation, dynamically adjusting processing steps, or introducing new components. A retail sales analysis pipeline must accommodate spikes in sales during promotional periods and respond to shifts in consumer preferences. Rigid designs limit the pipeline's ability to adapt to these shifts.
- Supporting Concurrent Operations and Increased Throughput
Modern data processing often necessitates concurrent operationshandling multiple tasks simultaneously to optimize efficiency. A scalable pipeline supports this by allowing multiple data streams to be processed concurrently, thus enhancing throughput. This might involve using multiple processing nodes or implementing parallel processing algorithms. For example, a financial transaction processing system must handle a massive influx of transactions in real-time. A non-scalable pipeline would struggle to maintain acceptable processing speeds and risk operational issues during peak hours.
- Modular Architecture and Component Reusability
A scalable pipeline architecture leverages modular components that can be reused and adapted across different tasks and stages. This approach promotes flexibility and reduces the complexity of modifications as processing needs evolve. A modular design facilitates updates, repairs, or the introduction of new components without requiring substantial rewrites or system redesign. This approach is crucial for managing complexity and accommodating growth within the pipeline.
In summary, scalability is not just a desirable feature but a fundamental requirement for a robust and effective data processing pipeline. A well-designed, scalable pipeline ensures long-term operational efficiency, maximizes the value extracted from data, and ultimately supports continuous growth and adaptation to the ever-evolving demands of modern data management.
6. Automation
Automation plays a critical role in the efficiency and effectiveness of a data processing pipeline, often referred to as a "bangl pipeline." Automated processes reduce manual intervention, minimizing human error and enhancing the speed and reliability of data flow. Streamlined workflows, driven by automation, contribute significantly to the pipeline's overall performance.
- Reduced Manual Intervention and Error Minimization
Automation significantly reduces reliance on manual processes, which are prone to errors. By automating tasks like data ingestion, transformation, and validation, the likelihood of human error is drastically minimized. This translates to more accurate data processing and subsequent analysis. Examples include automated data extraction from various sources, automated cleansing procedures, and automated quality checks throughout the pipeline. The result is heightened data reliability and reduced potential for costly downstream problems.
- Enhanced Speed and Efficiency in Data Processing
Automation directly accelerates the pipeline's processing speed. Automated tools can handle tasks significantly faster than manual methods, enabling faster insights and quicker responses to changing data. Examples encompass automated data transformations, streamlined data validation, and accelerated delivery mechanisms. This enhanced speed and efficiency are especially crucial in real-time applications and situations demanding quick responses to data. The increased velocity of data processing allows for more dynamic analysis and more timely decision-making.
- Improved Scalability and Adaptability
Automated pipelines are often more adaptable to changing data volumes and processing needs. Automated systems can adjust resource allocation and processing capacity as required, effectively handling surges in data without compromising speed or accuracy. This adaptability is vital in modern environments where data volumes and processing demands constantly evolve. An example includes adjusting computational resources dynamically in response to varying data loads, ensuring optimal pipeline performance regardless of data input. The ability to scale up or down based on demand contributes to a more robust and flexible pipeline.
- Cost Optimization and Resource Management
Automation can result in cost savings by reducing the need for human resources and the associated labor costs. Automated systems often require lower maintenance and operational expenses compared to human-intensive methods. Furthermore, automation promotes more efficient resource management, enabling optimal allocation of processing power. This leads to more cost-effective data processing, offering advantages in long-term sustainability. Examples include automating data warehousing processes, reducing the need for specialized personnel, and optimizing server utilization. The optimized use of resources and costs contributes to a more economical data management solution.
In conclusion, automation is not just a supplementary component of a data processing pipeline but an integral part of its core functionality. The benefitsreduced errors, enhanced speed, improved scalability, and cost-optimizationdirectly contribute to the pipeline's overall efficacy and value. Well-automated pipelines become more reliable, responsive, and cost-effective tools for deriving actionable insights from vast amounts of data. The integration of automation strategies within data pipelines, therefore, is crucial for enhancing the efficiency of modern data management operations.
7. Security
Security is not a separate add-on to a data processing pipeline, but an integral component deeply intertwined with its effectiveness. A robust "bangl pipeline" requires comprehensive security measures at every stage, from data ingestion to output delivery. Compromised security can lead to severe consequences, ranging from data breaches and regulatory fines to reputational damage and operational disruption. Protecting sensitive data throughout the entire lifecycle of processing is paramount, emphasizing the necessity of secure data handling practices.
Consider a financial institution's transaction processing pipeline. Security vulnerabilities in this pipeline could compromise sensitive customer data, leading to fraudulent activity and significant financial losses. In healthcare, a patient data processing pipeline that lacks robust security measures poses a substantial risk to patient privacy and safety, with potential legal ramifications. Similarly, in the realm of national security, a pipeline handling classified information necessitates the highest levels of security protection to prevent unauthorized access and potential espionage. In each of these examples, a weakness in the security protocols of the "bangl pipeline" directly translates to real-world harm and cost. The principle remains consistent across sectors: a secure data pipeline is critical for maintaining integrity and trustworthiness.
Understanding the crucial connection between security and a data processing pipeline requires a multifaceted approach. Security measures must extend beyond simple access controls; a proactive strategy encompassing data encryption, robust authentication, secure network configurations, and intrusion detection systems is essential. Regular security audits, incident response plans, and employee training programs are necessary to detect and mitigate potential threats. Furthermore, the evolution of cyber threats necessitates a constant vigilance and adaptability in security protocols. Maintaining the security of a "bangl pipeline" demands continuous monitoring, updates, and a commitment to staying ahead of emerging threats, to ensure that data integrity and confidentiality are paramount throughout the entire processing lifecycle.
8. Monitoring
Monitoring is an indispensable component of a data processing pipeline, often termed a "bangl pipeline." It's not merely an afterthought but a continuous process crucial for maintaining pipeline efficiency, identifying issues proactively, and ensuring the integrity of data. Without robust monitoring, potential problems such as data errors, processing bottlenecks, and security breaches might go undetected, leading to costly delays or severe consequences. Real-world examples illustrate this. A financial institution's transaction processing pipeline, for instance, requires real-time monitoring to detect fraudulent activity or system anomalies immediately. A healthcare system's medical data pipeline needs constant monitoring to guarantee patient data accuracy and compliance with regulatory standards. Failure to monitor these pipelines effectively can lead to significant financial losses, legal issues, or patient harm.
Monitoring within a data pipeline encompasses various aspects. Real-time performance metrics tracking processing speed, data volume, and error rates are critical. Identifying and addressing bottlenecks or delays early prevents significant issues from developing. Security monitoring actively detects unusual access patterns, unauthorized activities, or potential vulnerabilities. This proactive approach not only safeguards data but also helps prevent significant breaches or disruptions. Monitoring should be integrated into each stage of the pipeline, from data ingestion to output delivery. This allows for granular analysis of issues arising in any component. Detailed logs, alerts, and dashboards provide valuable insights into pipeline behavior. For example, in a streaming data pipeline, monitoring tools track data ingestion speed and the accuracy of transformations. This allows operators to quickly adjust resources or identify errors as they occur. In a batch processing pipeline, monitoring ensures jobs complete successfully within expected timeframes, enabling proactive problem resolution. This continuous feedback loop ensures the integrity, efficiency, and resilience of the overall system.
In conclusion, monitoring is not an optional extra but a fundamental necessity for a reliable and effective data processing pipeline. A proactive approach to monitoring allows organizations to identify and address potential issues before they escalate. The continuous assessment of performance metrics, security protocols, and data integrity is critical for maintaining the integrity, efficiency, and overall trustworthiness of a "bangl pipeline." By incorporating monitoring into each pipeline stage and actively addressing issues, organizations can mitigate potential risks and ensure the effective flow of data for informed decision-making, contributing to a stronger, more secure, and more reliable system.
Frequently Asked Questions (Data Processing Pipelines)
This section addresses common questions regarding data processing pipelines, often referred to as "bangl pipelines." Understanding these aspects is vital for establishing and maintaining effective data management systems.
Question 1: What is a data processing pipeline?
A data processing pipeline is a structured, sequential process for transforming and moving data. It involves a series of stages, each handling specific tasks, from data ingestion to output delivery. This systematic approach ensures data quality and consistency, enabling effective analysis and decision-making. Key stages often include ingestion, transformation, validation, and output delivery. Think of it as an assembly line for data, each step refining and preparing it for the next.
Question 2: What are the key stages within a typical data processing pipeline?
Typical stages include data ingestion, where data is collected from various sources; transformation, where data is prepared for analysis; validation, ensuring data quality and accuracy; and output delivery, where processed data is made available to users or other systems. Each stage plays a crucial role in the pipeline's effectiveness and overall efficiency.
Question 3: Why is data validation important in a data processing pipeline?
Data validation is critical for maintaining data quality and reliability. It involves checks and balances at each stage to ensure data accuracy, completeness, and consistency. This prevents issues from propagating downstream, leading to unreliable results and erroneous conclusions. Robust validation significantly contributes to trust in the data and the integrity of downstream analyses.
Question 4: How does automation improve data processing pipelines?
Automation streamlines processes, reducing manual intervention and human error. This increases efficiency, accelerates data processing, and enhances reliability. Automated pipelines often offer better scalability and adaptability to changing data volumes and processing demands. The benefits encompass reduced costs, increased accuracy, and improved overall performance.
Question 5: What role does security play in a data processing pipeline?
Security is paramount in a data processing pipeline. Protecting data from unauthorized access, breaches, and manipulation is crucial. Strong security protocols and measures are essential at each stage of the pipeline to ensure data integrity and confidentiality. Failure to prioritize security can have severe repercussions. Organizations must implement robust safeguards and adhere to relevant regulations to minimize risks and vulnerabilities.
In summary, a well-designed data processing pipeline, employing automation, robust validation, and secure handling, ensures the integrity, reliability, and efficiency of data processing workflows. Effective monitoring throughout the process further enhances the trustworthiness and value derived from the data.
Let's now explore the practical implementation of data processing pipelines in diverse industries.
Conclusion
A robust "bangl pipeline" is not simply a tool; it's a fundamental aspect of modern data management. The article explored the critical components of such a pipeline, from data ingestion to output delivery, emphasizing the importance of validation, security, automation, and scalability. Effective data pipelines are crucial for reliability, accuracy, and efficiency in processing large volumes of data. Each stage, from initial collection to final dissemination, demands meticulous attention to detail, safeguarding the integrity of the data and ensuring its usability for informed decision-making. The operational considerations outlined are paramount to achieving the desired outcomes from data analysis.
Moving forward, the development and implementation of sophisticated data processing pipelines will continue to be vital. Maintaining data integrity and security, particularly in sensitive industries, demands a proactive approach to pipeline design and maintenance. Addressing the evolving needs for scalability, automation, and adaptability in processing systems will be critical for successful data utilization. Understanding and refining these pipelines will be essential to organizations seeking to derive maximum value from their data assets. The future of effective data management depends on the continued development and optimization of robust and secure "bangl pipelines."
Dental Insurance & False Teeth: What You Need To Know
15% Of $1000: Quick Calculation
NNE Stock Prediction: 2024 Forecast & Analysis