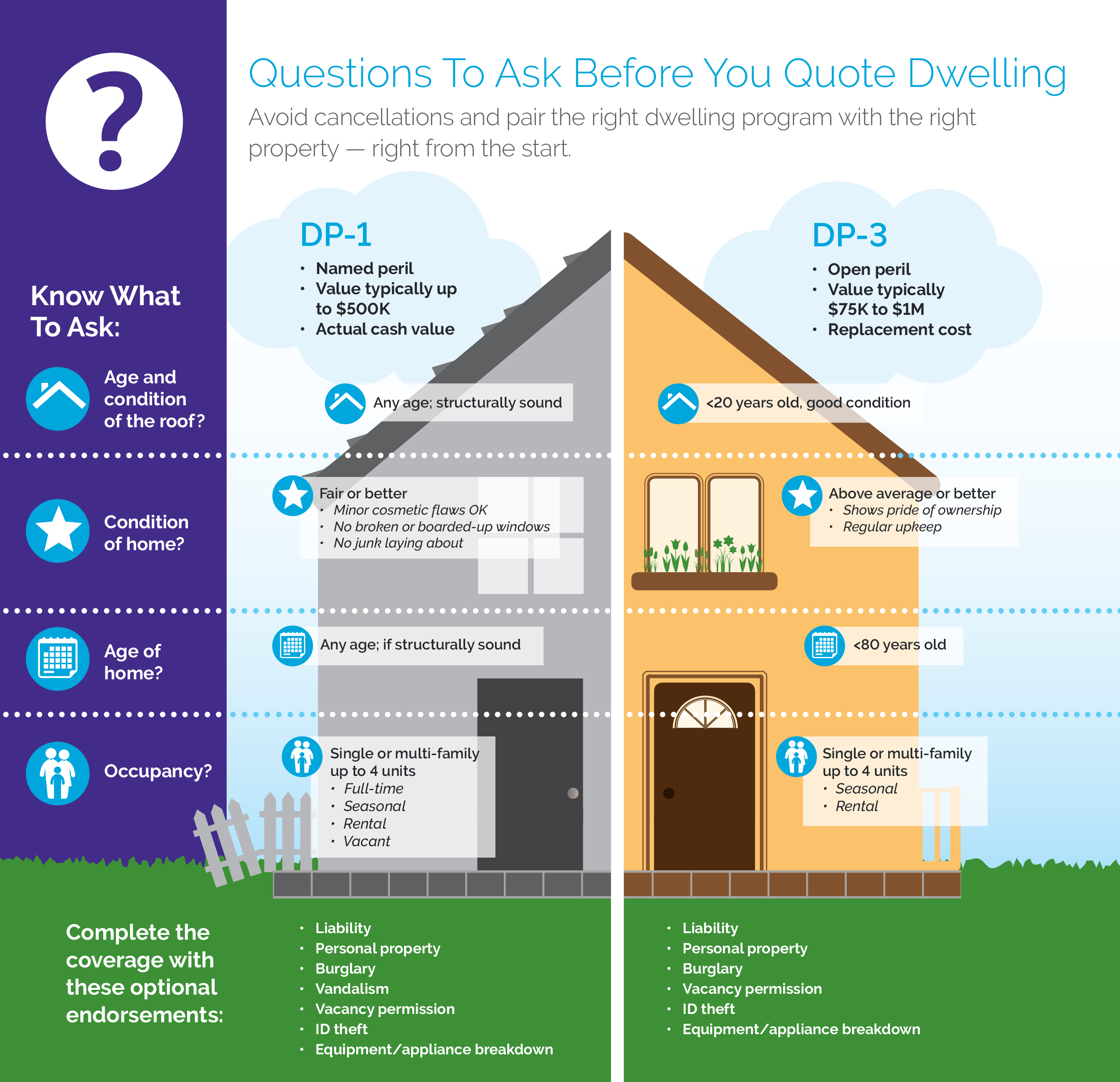
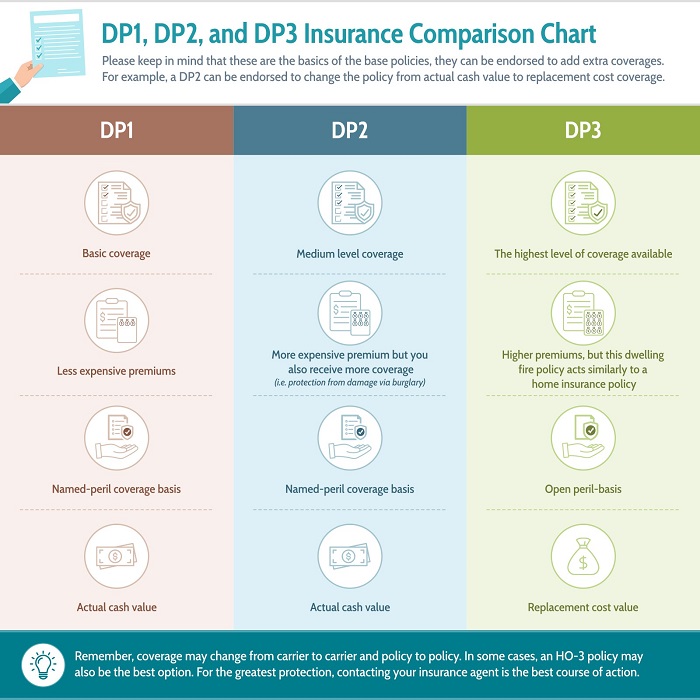
Comparing two distinct data processing methods, one focused on foundational principles and the other on advanced functionalities. Understanding their differences is crucial for choosing the appropriate approach in specific situations.
Data processing methodologies often vary in complexity and scope. One approach, often designated as the first level of processing ("Method 1"), might involve fundamental data cleaning and transformation techniques. This could include tasks such as handling missing values, converting data types, and standardizing formats. A more sophisticated approach, often referred to as the third level ("Method 3"), incorporates advanced algorithms and techniques for predictive modeling, complex analysis, or specialized data mining. Method 3 may include machine learning models or custom statistical procedures. The distinctions lie in the level of detail, type of analysis, and computational resources required.
Choosing between these methods depends entirely on the specific goals and requirements. Method 1, with its straightforward nature, is suitable for tasks needing basic data preparation, ensuring data quality for subsequent analyses. Method 3 is more appropriate for complex projects, like market trend prediction or risk assessment, where advanced modelling is crucial. The efficiency and accuracy of Method 3 can significantly enhance insights and decision-making, while Method 1's efficiency is important for large datasets to prevent processing bottlenecks. Historical context also influences the choice, with Method 1 often being the cornerstone of data preparation in many early data science projects, enabling the application of more complex techniques in Method 3. Modern data processing frameworks frequently support both approaches, enabling streamlined workflow and adaptability.
This discussion highlights the importance of recognizing diverse data processing approaches and the necessity of tailoring solutions to specific needs. It facilitates an understanding of how different methods contribute to the overall process and informs future strategies.
DP 1 vs DP 3
Understanding the fundamental differences between Data Processing Level 1 and Level 3 is crucial for effective data management. Each level offers distinct capabilities impacting the overall data workflow.
- Data Preparation
- Data Transformation
- Model Building
- Predictive Analysis
- Complexity
- Resource Requirements
Data Processing Level 1 (DP 1) focuses on foundational data preparation, ensuring data quality and structure. This often involves tasks like cleaning, transforming, and structuring data for analysis. Conversely, Data Processing Level 3 (DP 3) emphasizes advanced modeling and analytical techniques. It leverages complex algorithms for predictive modeling, statistical analysis, and data mining. The differing levels reflect the tradeoff between simplicity and complexity. DP 1 is essential for preparing data, while DP 3 provides deeper insights. For instance, a company needing basic sales figures might prioritize DP 1, but a company requiring advanced forecasting models would need DP 3. The complexity and resource requirements increase significantly between these levels, influencing the overall project duration and budget. Ultimately, selecting the appropriate level depends heavily on the specific objectives and the available resources.
1. Data Preparation
Data preparation is fundamental to both Data Processing Level 1 (DP 1) and Data Processing Level 3 (DP 3). The quality and thoroughness of data preparation directly impact the reliability and value of subsequent analyses, regardless of complexity. DP 1 often involves the initial stages of data cleansing, transformation, and structuring. This includes handling missing values, correcting inconsistencies, and formatting data for optimal use. DP 3, while employing sophisticated algorithms, ultimately relies on the integrity of data prepared at previous levels. Inaccurate or incomplete data will inevitably yield misleading results, regardless of the advanced analytics applied in DP 3.
Consider a company seeking to predict customer churn. Without meticulous data preparation (DP 1), identifying patterns in customer behavior becomes challenging. Inaccurate data, such as mislabeled customer segments or incorrect purchase history, could lead to flawed models and potentially costly decisions. Conversely, high-quality data preparation (DP 1) lays the groundwork for more accurate predictive models (DP 3). Data scientists can then apply machine learning algorithms for more detailed analysis and prediction, ultimately increasing the accuracy of churn predictions and the effectiveness of retention strategies. This demonstrates how foundational data preparation (DP 1) serves as a crucial prerequisite for advanced data processing (DP 3). Real-world examples abound, illustrating that neglecting data preparation at initial levels directly impacts the output of subsequent complex analyses.
Understanding the intricate connection between data preparation and diverse data processing levels is vital. Robust data preparation (DP 1) is not merely a preliminary step; it is a critical component of any successful data analysis, irrespective of the complexity or sophistication of the subsequent processing (DP 3). A comprehensive understanding of this link enables data professionals to establish standardized procedures for data quality and effectively utilize data resources, thereby significantly enhancing the trustworthiness and value of any data analysis project.
2. Data Transformation
Data transformation plays a pivotal role in both Data Processing Level 1 (DP 1) and Level 3 (DP 3). Its effectiveness directly impacts the quality and usability of data, influencing the outcome of analyses performed at either level. Proper transformation ensures data consistency, facilitates meaningful analysis, and ultimately guides informed decision-making.
- Data Standardization and Normalization
Standardization and normalization are crucial for DP 1, ensuring data consistency and compatibility. For instance, converting diverse date formats to a uniform format or normalizing different units of measurement (e.g., converting miles to kilometers) significantly enhances the usability of data for basic analyses. In DP 3, these processes remain foundational. However, standardization and normalization might extend to more complex transformations, such as feature scaling for machine learning algorithms, ensuring data features contribute proportionally to the model. This is vital to prevent certain features from overshadowing others in the analysis.
- Data Cleaning and Handling Missing Values
Data cleaning, including handling missing values, is paramount at both DP 1 and DP 3 levels. In DP 1, missing values might be imputed with simple techniques (e.g., mean or median imputation) to maintain dataset integrity for subsequent analyses. DP 3 necessitates more sophisticated methods for handling missing values, such as advanced imputation techniques, to avoid biasing complex models. This ensures data integrity for advanced modeling in DP 3, preventing the propagation of errors that could render insights unreliable.
- Feature Engineering
Feature engineering is a significant component of DP 3. It often involves creating new variables from existing ones, potentially using domain expertise, that can better reveal patterns and improve model performance. This process is typically not a primary component of DP 1. In DP 3, feature engineering becomes a key element for designing more intricate and effective models. For example, transforming raw sales data into time-based metrics, such as monthly sales growth rates, facilitates more nuanced predictions. This highlights the critical role of transformation in uncovering hidden patterns and improving predictive accuracy in more sophisticated analyses.
- Data Aggregation and Reduction
Data aggregation and reduction are common transformations in both DP 1 and DP 3. In DP 1, aggregating data (e.g., summarizing sales figures by region) simplifies analysis and reduces complexity. DP 3 frequently relies on this approach for efficient analysis and model training. For instance, dimensionality reduction techniques like Principal Component Analysis (PCA) are used to simplify complex datasets, making them more amenable to advanced analyses. This transformation is vital for reducing computational burdens while maintaining relevant information within complex data sets.
Ultimately, the nature of data transformation aligns with the processing level. DP 1 primarily focuses on ensuring data quality and basic preparation for analysis, whereas DP 3 often emphasizes transformations that enhance model performance and reveal deeper insights. The transformation processes in each level, while similar in core principles, vary in complexity and sophistication, reflecting the fundamental differences between these two processing stages.
3. Model Building
Model building is a critical component of data processing, directly influenced by the chosen level, whether DP 1 or DP 3. The type of model built and its complexity are intrinsically linked to the level of data preparation and processing previously undertaken. A robust model depends heavily on the quality of the data foundation, highlighting the crucial interplay between data processing levels and model creation.
- Model Complexity and Data Quality
The complexity of models directly correlates with the depth of data processing. DP 1 models, typically simpler in nature, rely on well-prepared, cleaned data to provide reliable results. Basic predictive models, like linear regression for trend analysis, benefit from high-quality, structured data for accurate outputs. In contrast, DP 3 models, which often involve intricate algorithms and machine learning techniques, necessitate extensive data pre-processing. Deep learning models, for example, demand vast datasets and sophisticated feature engineering, reflecting the substantial data transformations required to support their complexity.
- Resource Allocation and Model Performance
The resources required for model building vary significantly between DP 1 and DP 3. Simpler models (DP 1) demand fewer computational resources and less time to train. Sophisticated DP 3 models often require substantial computational power, extensive processing time, and specialized expertise to achieve optimal performance. This difference is crucial; while DP 1 models offer quick insights, DP 3 models provide deeper analysis and predictions, albeit at a cost in resources and time.
- Model Validation and Evaluation
Model validation and evaluation methodologies are influenced by the chosen processing level. DP 1 models often employ simpler validation techniques, like basic statistical tests, to assess their predictive capabilities. DP 3 models require more robust evaluation metrics and complex validation procedures, often involving cross-validation techniques and performance benchmarks like accuracy, precision, and recall. This highlights the increased rigor in model assessment and the need for more sophisticated methods in advanced processing environments.
- Data Exploration and Feature Engineering
The role of data exploration and feature engineering significantly differs depending on the chosen level. DP 1 often involves basic data exploration, ensuring data quality and addressing inconsistencies. DP 3 models often rely on extensive feature engineering to extract meaningful insights from raw data, constructing new variables or transforming existing features to improve model performance. This difference underscores the crucial role of data manipulation in driving the results of models created at the more complex processing level.
In summary, the type of model built and its performance are inextricably linked to the processing level. DP 1 models, built on a foundation of good data preparation, offer straightforward yet reliable insights. DP 3 models, built on extensive data processing and transformation, offer complex insights and accurate predictions, however, require significantly more resources and expertise. Careful consideration of the trade-offs between complexity and resources is paramount in selecting the appropriate processing level to achieve desired outcomes.
4. Predictive Analysis
Predictive analysis, a critical component of data-driven decision-making, is fundamentally intertwined with the distinction between Data Processing Level 1 (DP 1) and Data Processing Level 3 (DP 3). The effectiveness of predictive analysis hinges on the quality and scope of data preparation and processing. DP 1 lays the groundwork by ensuring data accuracy and consistency. DP 3 builds upon this foundation, incorporating advanced techniques for complex modeling and prediction. A robust predictive model relies on the accuracy of underlying data; flaws in initial processing (DP 1) undermine the validity of subsequent predictions (DP 3).
Consider a retail company seeking to predict future sales. DP 1 involves meticulous data collection, ensuring accurate records of past sales, customer demographics, and marketing campaigns. Data cleaning and transformation address inconsistencies and missing data. This foundational work is essential. Without a reliable data base prepared at this stage, sophisticated models used in DP 3, such as machine learning algorithms for forecasting, are likely to yield inaccurate results. Robust data preparation ensures the predictive model, whether a simple trend analysis or a complex time-series forecasting, provides reliable insight. Conversely, DP 3 leverages techniques like regression analysis, time series forecasting, or machine learning algorithms to model relationships and make accurate predictions. This step provides a more nuanced and potentially higher-precision forecast for the retail company. The enhanced predictive capabilities are directly linked to the quality of the underlying data processed in the initial stages (DP 1).
Consequently, a clear understanding of the relationship between predictive analysis and DP 1/DP 3 is crucial for achieving effective results. Failure to prioritize data preparation at DP 1 can lead to flawed predictions and costly errors in DP 3. Organizations need to recognize that effective predictive analysis demands attention to both fundamental data processing (DP 1) and advanced modeling (DP 3). The synergy between these two levels ensures that insights drawn from predictive analysis are reliable and actionable, enabling informed decision-making and strategic planning. This understanding, therefore, is not merely theoretical; it has practical implications for resource allocation, decision-making processes, and ultimate business success.
5. Complexity
The concept of complexity is central to understanding the differences between Data Processing Level 1 (DP 1) and Data Processing Level 3 (DP 3). The inherent complexity of tasks and data directly influences the methods and resources required for each level. This exploration examines how complexity manifests within these distinct data processing approaches.
- Computational Requirements
DP 1 typically involves straightforward data manipulation tasks, such as cleaning, transforming, and basic aggregation. These operations often require minimal computational resources. In contrast, DP 3 encompasses more complex algorithms and models, such as machine learning or deep learning. Consequently, DP 3 necessitates significant computational power, potentially involving high-performance computing resources, sophisticated software, and substantial processing time to handle complex datasets and execute advanced calculations.
- Data Structure and Volume
DP 1 often deals with relatively structured data, facilitating efficient data manipulation with standard tools. DP 3, however, frequently encounters unstructured or semi-structured data, demanding more sophisticated techniques for processing and analysis. Further, the volume of data involved can increase significantly in DP 3 applications, requiring scalable solutions and specialized tools to manage and process massive datasets. This difference in data characteristics necessitates distinct approaches to data handling and modeling.
- Algorithm Sophistication
DP 1 primarily relies on established, well-understood algorithms, often employing basic statistical techniques or standardized transformations. DP 3 necessitates the application of complex algorithms for model development and prediction, drawing from diverse fields like machine learning and deep learning. The mathematical complexity of these algorithms can significantly impact the model's accuracy and efficiency.
- Model Interpretability
DP 1 models are generally straightforward to understand and interpret, making their decisions and predictions transparent. Conversely, many DP 3 models, particularly complex machine learning models, can be notoriously opaque, making it difficult to trace the logic behind predictions. This "black box" nature of certain DP 3 models can present challenges in terms of explainability and trust, necessitating strategies for model interpretability.
In summary, the inherent complexity associated with DP 3 necessitates a higher degree of computational power, sophisticated algorithms, and advanced data management strategies. The increased complexity is directly linked to the need for more accurate and sophisticated analysis, prediction, and insight generation from diverse datasets. DP 1, on the other hand, focuses on foundational data processing, aiming for reliability and consistency through relatively simple, readily understood techniques. The distinctions in complexity highlight the different objectives and approaches of each data processing level, with DP 3 demanding significantly more resources and sophistication than DP 1 for achieving desired outcomes.
6. Resource Requirements
Resource requirements represent a critical consideration in the context of Data Processing Level 1 (DP 1) versus Data Processing Level 3 (DP 3). The varying complexity of tasks at each level directly impacts the necessary resourcescomputational power, personnel, and timedemanding careful consideration for effective project management and resource allocation. Understanding these resource disparities is pivotal for strategic planning and efficient execution.
- Computational Resources
DP 1 generally requires less powerful computational resources compared to DP 3. Simple data manipulation tasks, such as cleaning and transforming data, can be performed on standard hardware configurations. In contrast, DP 3 often involves intricate computations and complex algorithms demanding high-performance computing capabilities. Processing large datasets or implementing sophisticated machine learning models frequently requires specialized hardware, like clusters of servers or high-end graphical processing units (GPUs), significantly impacting the project budget. The difference in required computational power highlights the substantial resource gap between the two processing levels.
- Personnel Expertise
DP 1 typically requires personnel with basic data manipulation and analytical skills. Data entry, cleaning, and basic transformations can be managed by personnel with fundamental knowledge of data handling and tools. DP 3, on the other hand, demands personnel with advanced expertise in data science, machine learning, and sophisticated algorithms. Implementing complex models and optimizing for performance necessitate expertise in areas such as model selection, hyperparameter tuning, and deep learning architectures. The disparity in personnel requirements underscores the varying skill sets necessary for different processing levels.
- Data Storage Capacity
DP 1 typically operates on smaller datasets, requiring less storage capacity. Storing and managing pre-processed data for basic analysis is less demanding compared to DP 3. DP 3 often deals with substantial volumes of data, potentially needing specialized storage solutions to accommodate raw data, intermediate results, and trained models. The substantial difference in data volume significantly impacts storage requirements, often necessitating cloud storage solutions or distributed file systems to manage data efficiently.
- Project Timelines
DP 1 tasks typically have shorter project timelines due to the simpler data manipulations involved. Data preparation and basic analyses often complete quickly. DP 3 projects, conversely, are significantly more time-intensive, requiring extended periods for data processing, model training, and validation. Implementing advanced algorithms, training complex models, and optimizing for accuracy can take substantially longer, extending project durations considerably.
Careful consideration of resource requirements is crucial for effective project planning and execution. In choosing between DP 1 and DP 3, organizations must assess their available computational resources, personnel expertise, data storage capacity, and project timelines. The cost implications of each approach should also be thoroughly evaluated, factoring in the potential differences in time and personnel requirements. A comprehensive understanding of these resource aspects enables informed decision-making, ensuring alignment between project objectives and available resources, which is vital for success.
Frequently Asked Questions
This section addresses common queries regarding the differences between Data Processing Level 1 (DP 1) and Data Processing Level 3 (DP 3). Clear understanding of these distinctions is essential for effective data management and strategic decision-making.
Question 1: What is the fundamental difference between DP 1 and DP 3?
DP 1 focuses on foundational data preparation, ensuring data quality and structure. This includes data cleaning, transformation, and formatting. DP 3, conversely, emphasizes advanced modeling and analysis techniques. This involves complex algorithms, predictive modeling, and data mining to extract deeper insights.
Question 2: When is DP 1 appropriate, and when is DP 3 better suited?
DP 1 is suitable for tasks requiring basic data preparation, quality control, and ensuring data readiness for subsequent analyses. This is essential for projects needing reliable data for further processing or reporting. DP 3 is more appropriate for complex projects requiring advanced predictive modeling, in-depth analysis, or data mining for novel insights, such as market trend forecasting or risk assessment.
Question 3: What are the computational resource requirements for each level?
DP 1 typically requires fewer computational resources, often using standard tools and hardware for straightforward data manipulation. DP 3 necessitates significant computational power, potentially involving high-performance computing, specialized hardware (like GPUs), and advanced software for complex algorithm execution, model training, and handling large datasets.
Question 4: How does the complexity of algorithms differ between DP 1 and DP 3?
DP 1 primarily utilizes established algorithms for standard data transformations. DP 3 employs more complex algorithms, including sophisticated statistical models and machine learning techniques, which frequently involve advanced mathematical concepts. This increased complexity demands greater expertise and computational resources for optimal performance.
Question 5: What are the implications of choosing the wrong processing level?
Choosing an inappropriate processing level can lead to significant issues. Using DP 3 for simple data preparation tasks will be inefficient and unnecessary. Conversely, using DP 1 for a complex predictive modeling task will likely yield inaccurate or incomplete insights. Carefully considering the project's specific objectives and available resources is crucial for selecting the correct processing level.
In summary, understanding the distinctions between DP 1 and DP 3 is critical for effective data management. DP 1 ensures data quality and readiness, while DP 3 provides advanced insights through intricate modeling. Choosing the appropriate level depends on project goals, computational resources, and personnel expertise.
Next, we will explore the practical implementation of these levels in different industry contexts.
Conclusion
The exploration of Data Processing Level 1 (DP 1) and Data Processing Level 3 (DP 3) reveals a critical distinction in data management approaches. DP 1 emphasizes foundational data preparation, ensuring data quality and consistency through cleaning, transformation, and formatting. This fundamental step is essential for any subsequent analysis, regardless of complexity. DP 3, on the other hand, leverages advanced modeling and analytical techniques, including complex algorithms and machine learning, to extract deeper insights and predictions. The choice between these levels hinges on the specific project objectives and available resources. Computational requirements, personnel expertise, and project timelines are significant factors in the selection process. Both levels are integral parts of a comprehensive data workflow, each playing a vital role in ensuring effective data management and decision-making.
Effective data management requires a nuanced understanding of the distinct contributions of DP 1 and DP 3. Organizations must recognize the value of robust data preparation and leverage advanced modeling appropriately. Ignoring foundational data preparation (DP 1) can compromise the reliability of insights derived from sophisticated analyses (DP 3). Conversely, applying complex techniques (DP 3) to inadequately prepared data will yield suboptimal results. This understanding underscores the importance of a well-structured data lifecycle, incorporating both fundamental and advanced processing steps to maximize the value derived from data assets.
1902 Quarter Value: Worth & History
AMBBF Stock Ticker: Latest Quotes & News
Hilarious Man Holding Sign Memes: Viral & Funny!